Steps
Insert excel spreadsheet data into the two text areas labelled "Dataset 1" and "Dataset 2".
This can be done through either copying and pasting data directly from an excel spreadsheet, or dragging and dropping an Excel csv or xlsx file into the desired text area.
Note that currently only csv and xlsx files are accepted via drag and drop.
Note that both datasets must have column headers, with at least one column header that is identical (case-insensitive), for the program to function properly.


Determine the delimiter used in the datasets, either tab for regular excel files (Most common and default value) or comma for comma-separated values (CSV).


Note that this may be determined either before or after placing the data in the dataset text areas.
Both datasets must have the same delimiter formatting for the program to work.
If the Merging column(s) field isn't displaying the column headers properly, try changing the delimiter. If this doesn't fix the problem, make sure both datasets are formatted the same. If the problem persists, please contact CIT.
This will then populate the Merging columns field, which allows you to select the column or columns that should be used as a basis to join the two spreadsheets.


Once data is entered and the program determines they have a column header that is the same, it will populate this field to look similar to this. There may be more than one column the datasets share.


The column(s) will be highlighted when they are selected.
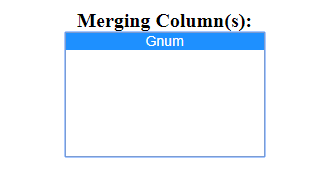
Hold the Crtl-button on Windows and the ⌘-key on MacOS while selecting to choose more than one column.
Once the the column or columns have been selected, push the blue "Merge" button to initiate the merging.
Note that data may be reordered row-wise upon merging in order to align similar rows
It will list all matches first, followed by unmatched values in the first set and then unmatched values in the second set.

This will then populate the Results text area towards the bottom once the merge has completed.
Note that after the merge has been completed, the program will insert a "_1" suffix to the columns from the first dataset and a "_2" suffix to the columns from the second dataset. This is to differentiate which data came from where after the merge, particularly in the case of identical column names that store different data.


To retrieve the data from the Results text area, it may be copy and pasted into a spreadsheet, drag and dropped into a spreadsheet, or downloaded as a csv file via the blue "Download Results" button underneath the text area.


Note that the data within the Results text area can not be modified directly from within the page by the user. To modify this data, download or move it into a local file on your computer to make the desired changes.
This result can be merged with a third dataset and so on, but this would require removing the "_1" or "_2" suffix from the desired merging column in the result dataset at the least.
The "Reset Values" button must be pressed before another merge may be performed.


During this step, the checkboxes to "Preserve Dataset 1" or "Preserve Dataset 2" may be unchecked to clear its respective dataset from the text area. This can facilitate entering a new dataset in the area.
Note that leaving the checkbox checked will keep the current dataset.


For example:
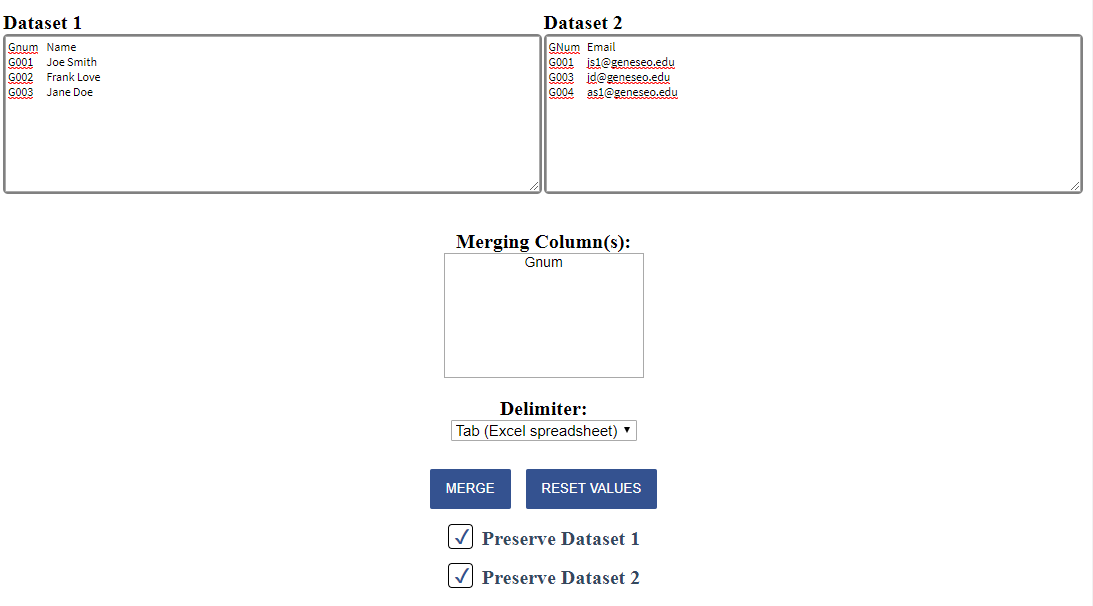
Paste the following data from an excel spreadsheet into Dataset 1 and Dataset 2 respectively
Dataset 1
Gnum Name G001 Joe Smith G002 Frank Love G003 Jane Doe
Dataset 2GNum Email G001 js1@geneseo.edu G003 jd@geneseo.edu G004 as1@geneseo.edu This will yield a page looking like this:
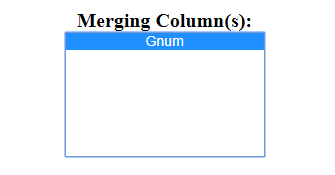
Then Select the merging column, in this case "Gnum"
Hit the "Merge" button and the Results field will be populated as follows:
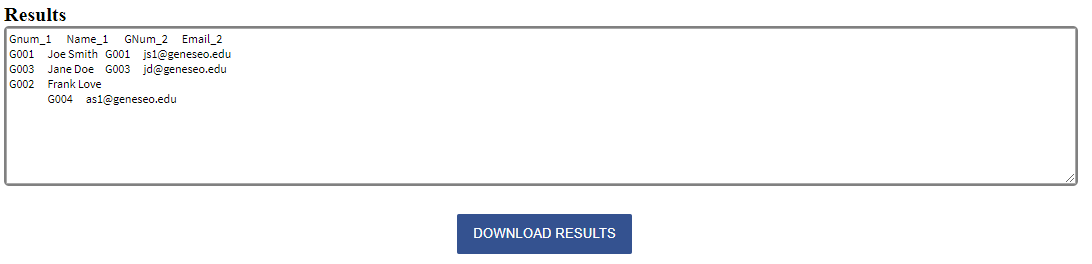
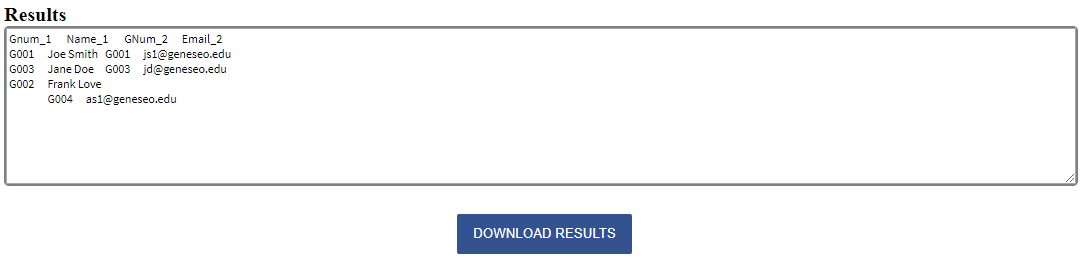
Once downloaded the table will appear as follows:
Notice that the two records with the same Gnum from each dataset appear first in the result with their columns joined on the same row.
Values in the datasets that have a match will always appear first in this manner, with the columns from the first dataset listed first, followed by the columns of the second dataset.
Then the record from the first dataset that has no match in the second dataset is listed by itself - the columns from the second dataset are empty.
Similarly, the record from the second dataset without a match in the first is alone with the columns from the first dataset empty.
...
| Page Properties | ||||||
|---|---|---|---|---|---|---|
| ||||||
|